火花监测
连接到 Spark 服务器
在“大数据工具”窗口中,单击
 并选择Spark。
并选择Spark。在打开的“大数据工具”对话框中,指定连接参数:

名称:连接的名称,用于区分其他连接。
URL:Spark 服务器的 URL。
您可以选择设置:
每个项目:选择仅为当前项目启用这些连接设置。如果您希望此连接在其他项目中可见,请取消选择它。
启用连接:如果要禁用此连接,请取消选择。默认情况下,启用新创建的连接。
启用隧道:创建到远程主机的 SSH 隧道。如果目标服务器位于专用网络中,但与网络中的主机的 SSH 连接可用,那么它会很有用。
选中该复选框并指定 SSH 连接的配置(单击...以创建新的 SSH 配置)。
启用 HTTP 基本身份验证:使用指定的用户名和密码进行 HTTP 身份验证的连接。
代理:选择是否要使用IDE 代理设置或是否要指定自定义代理设置。
填写设置后,单击测试连接以确保所有配置参数正确。然后单击“确定”。
使用正在运行的作业与 Zeppelin 建立连接
在涉及 Spark 的 Zeppelin 笔记本中,运行一个段落。
单击打开作业链接。在打开的通知中,单击链接。

如果您已连接到运行作业的 Spark 历史记录服务器,请单击选择连接并从列表中选择它。
在打开的“大数据工具”对话框中,验证连接设置并单击“测试连接”。如果连接成功,单击“确定”完成配置。

转到工具| 大数据工具设置页面的IDE设置 。CtrlAlt0S
打开大数据工具工具窗口(),选择 Spark 连接,然后单击
 。
。单击Spark 监控
 工具窗口任意选项卡中的。
工具窗口任意选项卡中的。
从 DAG 图导航到源代码
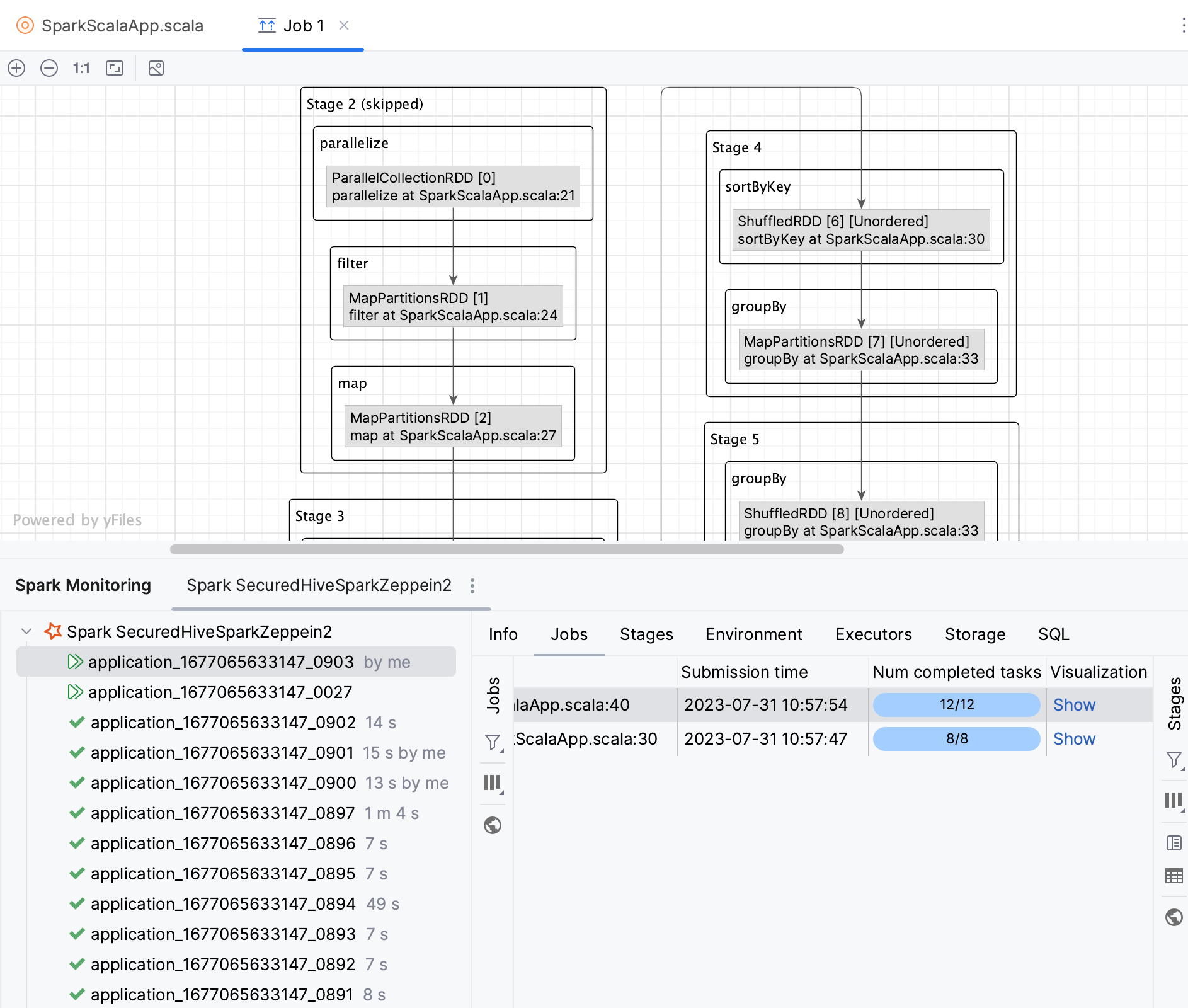
过滤掉监控数据
在Spark监控工具窗口中,使用以下过滤器来过滤应用程序:
过滤器:输入应用程序名称或 ID。
限制:更改显示的应用程序的限制或选择全部以显示所有应用程序。
已开始:按开始时间过滤应用程序或选择任意。
已完成:按完成时间过滤申请或选择“任意”。
 :仅显示正在运行或已完成的应用程序。
:仅显示正在运行或已完成的应用程序。

在Jobs、Stages和SQL选项卡中,您还可以按
状态过滤数据。
您随时可以![]() 在Spark监控工具窗口中单击 ,手动刷新监控数据。或者,您可以使用“刷新”按钮旁边的列表配置在特定时间间隔内自动更新。
在Spark监控工具窗口中单击 ,手动刷新监控数据。或者,您可以使用“刷新”按钮旁边的列表配置在特定时间间隔内自动更新。
感谢您的反馈意见!